
Objectifs et défis
Le théâtre dialectal en alsacien représente une tradition dans laquelle les genres populaires et humoristiques sont prédominants. Quelles sont les tendances majeures de cette tradition en termes de technique dramatique et types de personnages ? Quels sont les lieux géographiques pertinents ? Dans quelle mesure les pièces permettent-elles de documenter les pratiques sociolinguistiques de leur époque?
Afin de répondre à ces questions et d’effectuer des analyses quantitatives, un corpus de grande taille représentatif de la tradition est requis, ainsi qu’une annotation du corpus qui reflète les variables à étudier : origine géographique des pièces et auteurs, lieux où se déroulent les pièces, période et genre dramatique. Concernant les personnages, des attributs comme leur profession, position sociale, origine, sexe ou âge doivent être disponibles. Il est également nécessaire de formaliser la structure des pièces, en indiquant les divisions en actes ou scènes, les répliques et les personnages, et les didascalies.
Notre projet vise à créer un corpus possédant de telles caractéristiques, encodé en format TEI (Text Encoding Initiative), dont le module Performance est adapté à ces besoins. Nous travaillons sur un ensemble représentatif de pièces, récemment numérisées par la Bibliothèque Nationale et Universitaire de Strasbourg, dont nous avons commencé l’océrisation et encodage TEI.
Un corpus de ce type permettra une approche de distant reading ou macroanalyse sur le théâtre alsacien. Ces approches ont été appliquées aux principales traditions dramatiques européennes, comme en témoigne le numéro monographique sur ce sujet dans la Revue d’Historiographie du Théâtre (2017). Or, elles ne sont pas possibles à l’heure actuelle pour l’alsacien, en raison du manque du corpus approprié. Le projet MeThAL cherche à combler ce vide.
À cette fin, nous appliquerons des techniques de traitement automatique des langues et de représentation documentaire ainsi que des technologies web qui contribueront à la navigabilité du corpus.
Défis
L’énorme variation orthographique de l’alsacien présente, comme pour toute langue peu dotée, des défis spécifiques en Traitement automatique des langues (TAL). Ces défis soulignent des besoins imparfaitement couverts par les outils d’analyse textuelle existants, orientés prioritairement vers les langues majoritaires. Dans ce sens, le projet exploitera et contribuera aux ressources du projet RESTAURE pour les langues régionales de France.
Productions
Publications et communications
-
Qinyue Liu, Pablo Ruiz, Delphine Bernhard. (2023). Towards emotion analysis for Alsatian theater. Poster présenté à Computational Humanities Research, Paris, France. Poster: ⟨hal-04213017⟩. Résumé: ⟨zenodo.8404252⟩
-
Pablo Ruiz. (2023). The MeThAL Alsatian theater corpus and related resources: Work done and perspectives. 5èmes journées scientifiques du Groupement de Recherche Linguistique Informatique Formelle et de Terrain (LIFT) : 113-118. Nancy, France. ⟨hal-04391970⟩
-
Pablo Ruiz, Delphine Bernhard, Andrew Briand, Carole Werner. (2022). Computational drama analysis from almost zero electronic text: The case of Alsatian theater. Workshop on Computational Drama Analysis, Cologne, septembre 2022. [preprint]
-
Pablo Ruiz, Helena Bermúdez. (2022). Feature structures for character social variable annotation and an application to Alsatian theater. Poster accepté à TEI 2022 - Text Encoding Initiative Conference (Session posters virtuels). Septembre 2022. Newcastle, Royaume Uni. ⟨10.5281/zenodo.7110069⟩ ⟨hal-036762679⟩
-
Delphine Bernhard, Pablo Ruiz. (2022). ELAL: An emotion lexicon for the analysis of Alsatian theatre plays. LREC 2022, Language Resources and Evaluation Conference. ⟨hal-03655148⟩
-
Pablo Ruiz, Carole Werner, Delphine Bernhard. (2022). The benefits of increasing the digital availability of Alsatian theater. Digital Humanities 2022 : 557-560. ⟨10.5281/zenodo.7014965⟩ ⟨hal-03660481⟩
-
Pablo Ruiz, Carole Werner. (2022). Théâtre alsacien : Personographie en TEI et navigation du corpus selon les attributs sociaux des personnages. Humanistica 2022. ⟨hal-03660506⟩
-
Pablo Ruiz, Carole Werner, Delphine Bernhard, Pascale Erhart, Dominique Huck. (2021). MeThAL : Ressources numériques pour une relecture du théâtre en alsacien. Poster présenté à 10 ans avec CAHIER: Des corpus d’auteurs pour les humanités numériques à leur exploitation numérique, juin 2021, Bordeaux, France. ⟨10.5281/zenodo.4908212⟩. ⟨hal-03255403⟩
-
Pablo Ruiz, Carole Werner. (2021). Exploration du théâtre alsacien à travers ses listes de personnages pendant la période 1870-1940. Humanistica 2021 : 27-29, Rennes, France. ⟨10.5281/zenodo.4762732⟩ ⟨hal-03226579⟩ [slides]
-
Pablo Ruiz, Delphine Bernhard, Carole Werner. (2020). Création d’un corpus FAIR de théâtre en alsacien et normalisation de variétés non-contemporaines. 2èmes journées scientifiques du Groupement de Recherche Linguistique Informatique Formelle et de Terrain (LIFT) : 32-43. Montrouge, France. ⟨10.5281/zenodo.4323301⟩ ⟨hal-03047152⟩ [slides]
-
Pablo Ruiz, Delphine Bernhard, Pascale Erhart, Dominique Huck, Carole Werner. (2020). MeThAL : Vers une macroanalyse du théâtre en alsacien. Humanistica 2020, Bordeaux, France. ⟨10.5281/zenodo.3788019⟩. ⟨hal-02564694⟩
Corpus
Une interface pour explorer le corpus est sur https://methal.eu/ui/ (lecture des pièces, filtrage selon les caractéristiques des pièces et des personnages).
Concernant les sources TEI :
-
Elles sont mises à disposition dans le dépôt methal-sources à mesure que l’encodage avance
-
La publication pérenne (avec DOI) s’effectue à travers une collection sur la plateforme Nakala
À part des pièces encodées, une personographie en TEI décrivant plus de 2 350 personnages issus d’environ 230 pièces a été publiée ; les personnages y sont décrits avec des variables sociales comme leur âge, genre, activité professionnelle ou classe sociale
Logiciels
-
FETE: Fast Encoding of Theater in TEI. Encodage automatique de TEI à partir de sorties OCR par étiquetage de séquences.
-
EDYTHA: Emotion Dynamics in Theater in Alsatian. Étiquetage du lexique émotionnel et son évolution au cours de l’intrigue dans des pièces de théâtre en alsacien. Basé sur l’outil TED et le lexique ELAL
Présentations
-
Towards the computational analysis of a peripheral literary tradition: The case of Alsatian theater. November 2023, Institute of Contemporary History. Universidade NOVA de Lisboa, FCSH. Atelier organisé par le projet REWIND
-
Analyze peripheral literatures — or create the resources trying. June 2023. Séminaire au CiTIUS, Universidade de Santiago de Compostela
-
Réutilisation et création de données ouvertes interopérables pour l’étude du théâtre en alsacien dans le cadre du projet MeThAL. Open Access Month. Octobre 2022, Université de Strasbourg. [vidéo] (début 0:50:25)
-
De l’OCR à la TEI dans un corpus de théâtre alsacien dans le cadre du projet MeThAL. 2èmes rencontres Estrades-Eveille, septembre 2022, Université de Strasbourg
-
MeThAL : Ressources numériques pour une relecture du théâtre en alsacien. Journée d’étude « Théâtre dialectal », mai 2022, Department of German Studies, Université de Strasbourg
-
MeThAL : Vers une macroanalyse du théâtre en alsacien. Séminaire de la Féderation de Recherche Langage et Cognition, février 2021, Université de Strasbourg : [slides]
-
MeThAL : Vers une macroanalyse du théâtre en alsacien. Séminaire du laboratoire LiLPa, décembre 2019, Université de Strasbourg : [slides]
Mémoires
-
Yang, H. (2022). Détection de la variation graphique dans une langue non standardisée : le cas des dialectes alsaciens. Mémoire de Master 2 Sciences du Langage, parcours Industries de la langue. Université Grenoble Alpes. Tuteur universitaire : Claude Ponton (UGA). Encadrement du stage : Pablo Ruiz Fabo (Unistra), Alice Millour (Paris 8), Delphine Bernhard (Unistra) . ⟨dumas-03794680⟩
Événements
-
23/06/2023 : Journée d’études « Théâtre amateur et ressources numériques : Vecteurs de stabilisation de la pratique du dialecte ? » [programme]
Actualités
-
Le carnet de recherche de la Bnu en parle :
-
Lancement du projet
-
Travaux sur la distribution des personnages des pièces
-
Publication des premières 25 pièces encodées en TEI
-
-
Nouveau project relié à MeThAL ! En 2023-24, nous développerons également le projet TheALTReS (Comparaison entre le Théâtre ALsacien et ses TRaditions dramatiques Sources), soutenu par la MISHA dans le cadre de son programme scientifique.
-
La plate-forme DraCor (Drama Corpora) a accepté d’accueillir les pièces encodées, rendant ainsi des premières analyses disponibles :
-
dracor.org/als : Lecture des pièces encodées, réseaux et relations entre les personnages
-
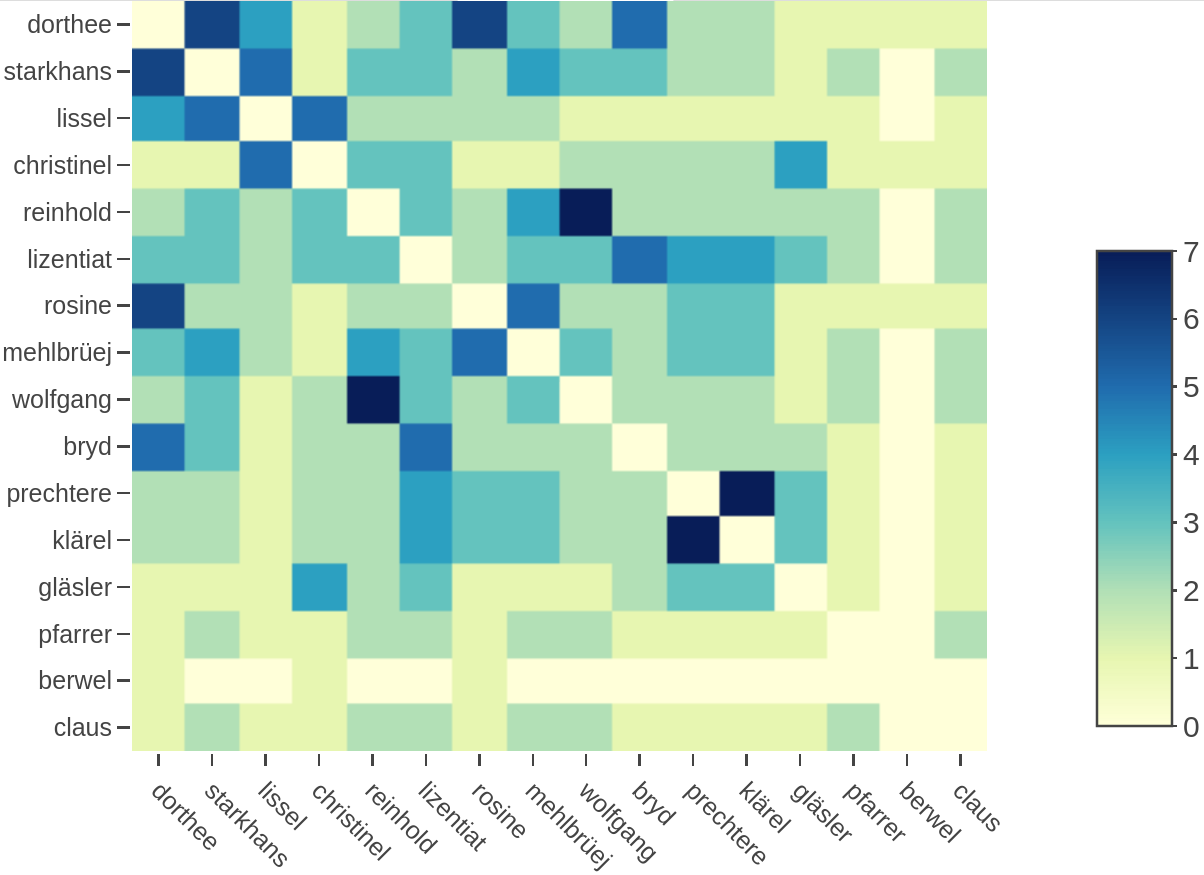
shiny.dracor.org : Visualisation de différentes métriques d’interaction entre les personnages. P. ex. la matrice d’interaction ci-dessous pour les personnages de Der Pfingstmontag (Arnold, 1816).
-
Participants
Les participants au projet sont membres du laboratoire LiLPa : Pablo Ruiz (responsable), Delphine Bernhard, Pascale Erhart, Dominique Huck and Carole Werner.
Nous sommes également en lien avec le Datalab de la Bnu et le projet a fait l’objet d’un premier examen par GIS Corpus de la Bnu.
Nous remercions particulièrement les nombreux.ses stagiaires de plusieurs filières et parcours (Master Technologies des langues et Sciences du langage, Licences LLCER, LEA et Informatique) que nous avons l’occasion d’accueillir dans le projet. Parmi les étudiant.e.s Unistra : Nathanaël Beiner, Lena Camillone, Hoda Chouaib, Audrey Deck, Valentine Jung, Salomé Klein, Audrey Li-Thiao-Té, Kévin Michoud et Vedisha Toory. Au-delà : Andrew Briand (Université de Washington, via IFE Strasbourg), Barbara Hoff (Université d’Édimbourg), Qinyue Liu et Heng Yang (Université Grenoble Alpes).
Rejoignez-nous
Vous êtes intéressé.e à l’encodage TEI, application de technologies linguistiques à l’alsacien, édition électronique, ou à la linguistique et littérature alsaciennes ? Intéressé.e par un stage autour de ces sujets ?
Vous avez une autre question sur le projet ?

À propos du site
-
Ce site web est géré par Pablo Ruiz Fabo (Université de Strasbourg)
Hébergement
-
Le site est hébergé par l’Université de Strasbourg
Licence
-
Le contenu dont l’URL commence par https://methal.pages.unistra.fr est sous licence CC-BY-4.0
-
Les licences pour le contenu disponible sur l’interface d’exploraton du corpus (https://methal.eu/ui/), également accessible ici depuis les options Explorer le corpus et Interface du menu, sont spécifiées sur https://methal.eu/ui/about